Investigación
El método que descubre la depresión a partir de las palabras escritas
Basado en técnicas de aprendizaje automático, identificar signos de depresión a través del análisis de texto

La depresión es una enfermedad mental debilitante que afecta a más de dos millones de personas, disminuyendo su calidad de vida y bienestar general. Es una de las condiciones de salud mental más comunes y puede afectar a personas de cualquier edad, género o condición socioeconómica. Se caracteriza por una profunda tristeza, una disminución del interés o placer en actividades previamente gratificantes, y una significativa pérdida de energía o fatiga, entre otros síntomas. La creciente prevalencia de los trastornos de salud mental ha subrayado la necesidad de enfoques innovadores para detectar y abordar la depresión.
En este contexto, un equipo de investigadores de la Escuela Técnica Superior de Ingenieros de Telecomunicación (ETSIT) de la Universidad Politécnica de Madrid (UPM) ha desarrollado un método basado en tecnologías de aprendizaje automático que permite identificar de forma precoz los síntomas de depresión analizando las palabras escritas en un texto. Las conclusiones de su trabajo se han publicado en la revista Applied Sciences.
En una nota difundida este jueves los investigadores explican que con este método se podría avanzar "significativamente" en la detección temprana de signos de depresión, introduciendo un enfoque basado en aprendizaje automático que consigue resultados prometedores en la detección de la depresión en los textos. Este enfoque no solo demuestra su eficacia en términos de rendimiento, sino que también se presenta, según los investigadores, como una solución "práctica y accesible" para la detección temprana de signos depresivos dentro del contenido digital.
El investigador Sergio Muñoz, del Grupo de Sistemas Inteligentes de la Universidad Politécnica, ha destacado la relevancia que tendría la utilización de este método en ambientes, plataformas o foros educativos en las que los alumnos escriben y se comunican por escrito, y las posibilidades que podría tener para la detección temprana de los síntomas de depresión. En declaraciones a EFE, Muñoz ha explicado que el trabajo que han realizado ha sido experimental y han utilizado para ello datos extraídos de la plataforma Reddit, un agregador de contenidos que funciona en todo el mundo como un foro social en el que millones de usuarios pueden añadir textos y votar a favor o en contra de lo que se publica, propiciando de esa manera que unos contenidos destaquen frente a otros.
Muñoz ha insistido en que el método está en fase experimental y no se está aplicando ni utilizando con usuarios reales, y ha explicado que un estudio similar les permitió detectar síntomas de estrés y de ansiedad y comprobar cómo el uso de algunas palabras (como miedo, ataque, lucha, muerte, u otras malsonantes) estaban asociadas a esos niveles de estrés. A largo plazo, y tras superar las diferentes fases experimentales, un método de estas características, ha señalado el investigador, podría integrarse en diferentes plataformas -redes sociales e incluso expedientes o informes médicos- para lograr una utilidad real y práctica que permitiera detectar de forma temprana esos síntomas de depresión.
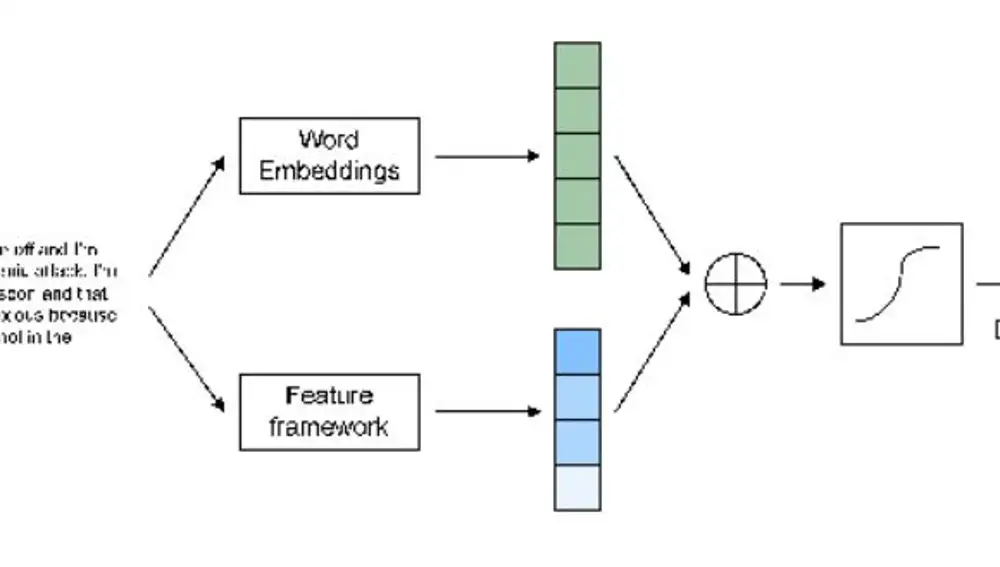
Los investigadores han explorado la eficacia de los métodos tradicionales de aprendizaje automático en la detección de la gravedad de los signos de depresión. Frente a modelos más complejos que requieren recursos computacionales más complejos, su enfoque consigue un equilibrio perfecto entre rendimiento y eficiencia. Para ello, se ha introducido en la investigación un marco de trabajo muy completo de características basadas en recursos léxicos, que facilita la organización de las características textuales, integrando las señales lingüísticas, las expresiones emocionales y los patrones cognitivos para proporcionar una comprensión global de los indicadores lingüísticos asociados a la depresión.
Para ello, se extrajeron un gran número de características y se organizaron en cuatro conjuntos: afectivas, temáticas, sociales y sintácticas. Los resultados sugieren que las características afectivas destacan en la clasificación de texto para la detección de depresión, pero la inclusión de características sociales, sintácticas y temáticas mejora el rendimiento de manera significativa. La efectividad del enfoque propuesto se evalúa con un estudio experimental utilizando dos conjuntos de datos públicos en inglés de plataformas de redes sociales.
✕
Accede a tu cuenta para comentar