



Tecnología
VALL-E, la nueva IA de Microsoft que imita cualquier voz a partir de un audio de tres segundos
Este nuevo modelo de texto a voz podrá trabajar con otros modelos de inteligencia artificial generativa como ChatGPT
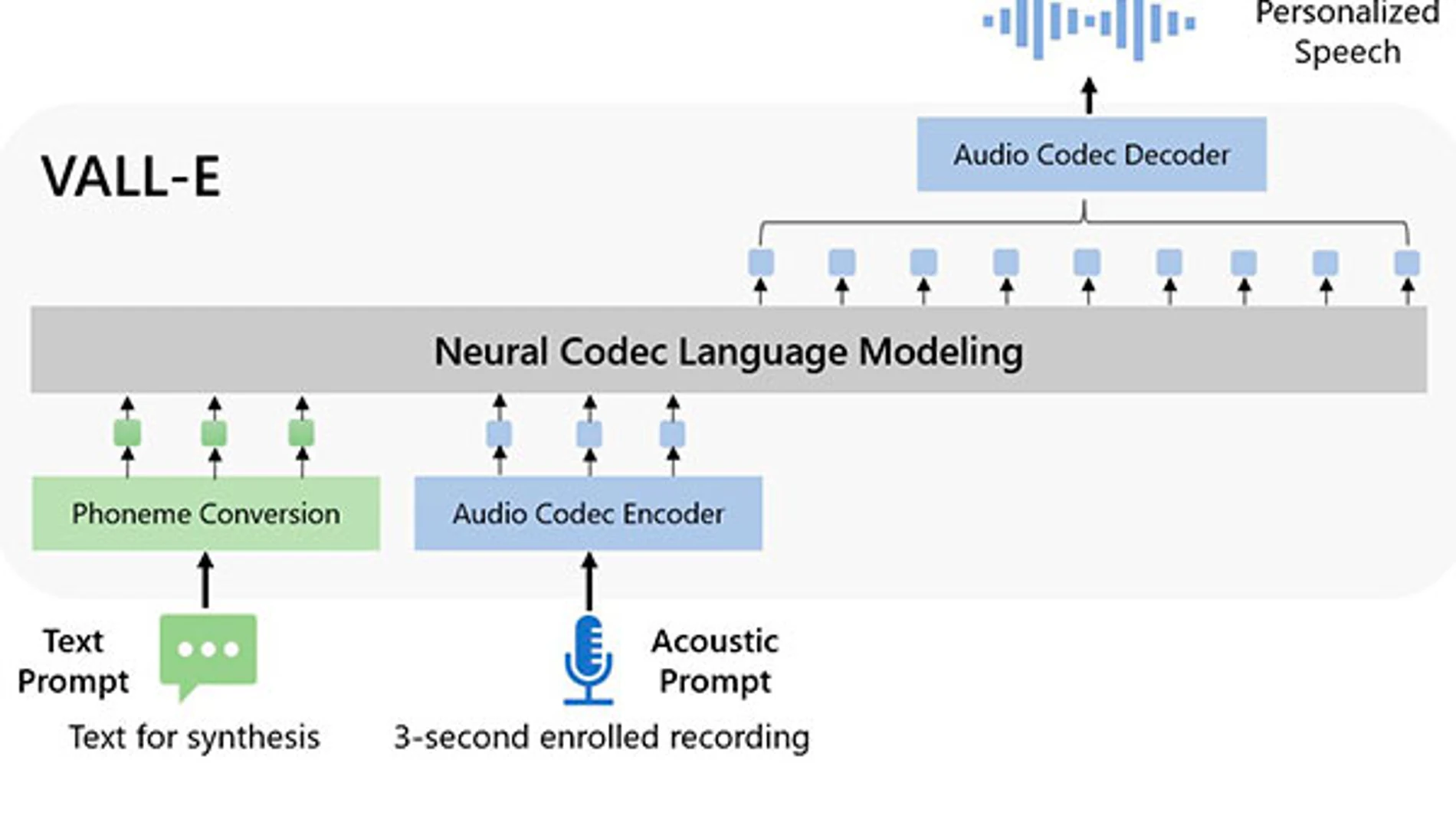
2022 fue el año de las inteligencias artificiales generativas, con modelos como DALL-E o ChatGPT que han revolucionado la creación de contenido en Internet, y 2023 comienza fuerte también. Microsoft ha presentado una nueva inteligencia artificial generativa que puede imitar la voz de cualquier persona a partir de un clip de audio de solo tres segundos. Su nombre es VALL-E, en obvia referencia a la mencionada DALL-E, la IA generativa de imágenes a partir de texto de OpenAI.
VALL-E es lo que Microsoft denomina “modelo de lenguaje de códec neuronal” y a partir de un fragmento de audio tan breve es capaz de analizar como suena una persona, dividir la información en componentes diferenciados llamados tokens y utilizar el conjunto de datos con el que ha sido entrenado la IA para resolver como sonaría esa voz pronunciando cualquier frase que se le indique por texto. En el proceso emplea una tecnología de compresión de audio llamada EnCodec que Meta anunció el pasado octubre y que permite comprimir el audio 10 veces que más que el formato MP3, sin pérdida de calidad.
Microsoft ha lanzado una web explicando las características de VALL-E y con una amplia variedad de ejemplos de sus capacidades. Cada uno de ellos muestra el texto que va a reproducir VALL-E, el audio de tres segundos con la voz a imitar (Speaker Prompt) con una frase cualquiera, un segundo clip de audio de la misma voz (Ground Truth) leyendo el texto del primer campo para comparar con el resultado final, otro audio (Baseline) con el resultado buscado realizado por un modelo texto a voz convencional y, por último, el resultado final generado por VALL-E.
El modelo de Microsoft es capaz de replicar el timbre vocal del hablante, su tono emocional y el entorno acústico del audio con la voz original, de forma que si la grabación corresponde a una llamada de teléfono, el audio generado por VALL-E también sonará así.
El resultado no es perfecto, pero sí sorprendente consiguiendo en muchos de los ejemplos que sea posible confundir ambas voces, la original y la generada por la IA a partir de esos tres segundos de audio.
VALL-E ha sido entrenada con una biblioteca de audio proporcionada por Meta llamada LibriLight que contiene 60.000 horas de grabaciones de voces en inglés pertenecientes a más de 7.000 personas, un conjunto de datos “cientos de veces más grande que los empleados en modelos existentes”. La IA consigue los mejores resultados cuando la voz que debe imitar es más parecida a con las que ha sido entrenada.
Entre las utilidades que Microsoft describe para VALL-E se encuentran las aplicaciones de texto a voz, la edición de grabaciones de voz en las que se podría cambiar el contenido a partir simplemente de un texto y la creación de contenidos de audio combinándolo con otros modelos de inteligencia artificial generativa como ChatGPT.
“Los resultados del experimento muestran que VALL-E supera significativamente al sistema de TTS [síntesis de texto a voz, por sus siglas en inglés] de última generación en términos de naturalidad del habla y similitud del hablante”, señala el equipo que desarrolla WALL-E en la página web.
El potencial para un uso dañino de una IA como VALL-E es evidente y Microsoft no tiene planes, por el momento, de liberar su uso como hace, por ejemplo, OpenAI con sus modelos. A este respecto, los responsables de VALL-E señalan que “dado que VALL-E puede sintetizar la voz que sustenta la identidad del hablante, conlleva riesgos potenciales por el uso indebido del modelo como falsificar la identificación por voz o hacerse pasar por un hablante específico. Para mitigar tales riesgos, es posible construir un modelo de detección para discriminar si un clip de audio fue sintetizado por VALL-E. También pondremos en práctica los Principios de IA de Microsoft cuando desarrollemos más los modelos.”
✕
Accede a tu cuenta para comentar


